These notes are based on our initial meeting on 24 January 2012. The aim was to collect some use cases and have an initial idea on what needs to be done to extend or revise the existing Audio Features Ontology.
Topics discussed¶
A rough list of topics discussed during the first meeting:
- What are the main research use cases for an Audio Features Ontology (AF) ?
- Are they served well by the existing AF ?
- If not, what are the most important extensions we need to do?
- Does the fundamental structure of the ontology need to be changed?
- What is the relation of AF to existing software, including:
- software like: Sonic Annotator, Sonic Visualiser, SAWA, AudioDB other tools...
- and projects like: OMRAS2, EASAIER, SALAMI, new Semantic Media/Semantic Audio grants...
- Personal Objectives: what are we going to do with a modified/re-engineered ontology?
Use cases:¶
Use cases discussed so far:
Thomas:
- drive audio effects -> adaptive effect (controlling effects)
- KM like use case: association of audio effects and audio features e.g. pitch shifter won’t change onsets
- part of the AFX ontology
- more audio features
- technical classification of audio effects
- Finding structure, repeated sequences of features
- Beat related stuff, BPM (tempo, major/minor is it an audio feature)
- Chords, Chord sequences => Chord ontology
- Melody and notes
- Improve SAWA
- Facilitate the development of intelligent music production systems
- Release large content based metadata repositories in RDF
- Re-release the MSD in RDF (??)
- Deploy a knowledge based environment for content-based audio analysis based on the concept of the Knowledge Machine that can combine multiple modalities
- Research reproducibility using Ontologies as a model to exchange research data.
Fundamental structure of the existing AF Ontology:¶
The Audio Features Ontology currently provides a core model which distinguishes between audio features based on two attributes:
- Temporal characteristics
- Data density
The first dichotomy allows for describing features either instantaneous events (e.g. note onsets, tempo change), or features with a known time duration (notes, structural segments, harmonic segments, the extent of an STFT or Chromagram frame).
The second dichotomy addresses a representational issue, and allows for describing how a feature relates to the extent of an audio file:- whether it is scattered and irregularly occurs during the course of a track (i.e. sparse),
- or occurs regularly and have a fixed duration (i.e. dense).
Alternative conceptualisations and some examples are summarised below:
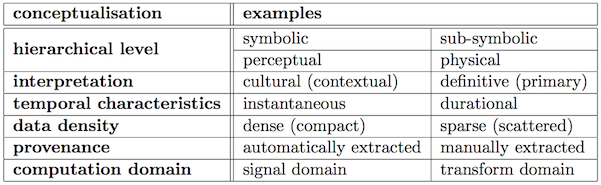
Fig 1. Conceptualisations of content-based features. [maybe commit my relevant thesis chapter]
The main scope of the existing ontology is to provide a framework for communication and to describe the association of features and audio signals. It does not classify features, describe their interrelationships or their computation. It deals with data density, and temporal characteristics only and differentiates between dense signal-like features of various dimensionality, (chromagrams, detection functions) and sparse features that are scattered across the signal timeline. This core model is shown in the following diagram:
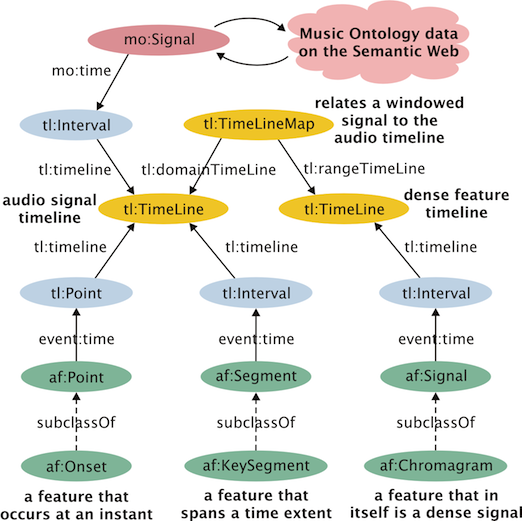
Fig. 2. Core model of the existing Audio Features Ontology
RDF Example:¶
AF heavily relies on the event and timeline ontologies to refer to event in time and timelines corresponding to the duration of an audio signal or a dense signal-like feature. Here's an RDF example produced by SAWA/Sonic Annotator describing temporal segments using the ontology:
<http://isophonics.net/sawa/audiofile/temp/AU775621fe> a mo:AudioFile ;
dc:title """music-test.wav""" ;
mo:encodes :signal_1.
:signal_1 a mo:Signal ;
mo:time [
a tl:Interval ;
tl:onTimeLine :signal_timeline_1
] .
:signal_timeline_1 a tl:Timeline .
:event_2 a <http://purl.org/ontology/af/StructuralSegment> ;
event:time [
a tl:Interval ;
tl:onTimeLine :signal_timeline_1 ;
tl:at "PT19.600000000S"^^xsd:duration ;
tl:duration "PT10.500000000S"^^xsd:duration ;
] ;
af:feature "9" .
Open issues:¶
Some important questions to be decided on:
Domain boundaries and scope:¶
- What is the ideal domain a revised AF?
- Are Musicological concepts outside the domain of an AF ?
- Should the currently included speech features moved to another ontology?
- They were added only to satisfy EASAIER requirements.
- How about Physical features:
- Acoustic features,
- Perceptual Features,
- DSP type feature,
- Musical Features (musically meaningful features related to acoustics)
- The scope of the revised ontology may be:
- Facilitate data-exchange for various purposes: (e.g. Linked Open Data, Research reproducibility, etc...)
- Facilitate building intelligent/knowledge-based systems:
- How expressive the Ontology should be?
- What kind of reasoning services should be supported?
What are the strength and weaknesses of the existing ontology?¶
- Does it serve us well?
- For example, loudness is defined as a segment in AF, and it does not fit a perceptual attribute well.
- What depth do we want ? (both in terms of scope and the level of detail)
- do we want to describe feature extraction workflows using this or another ontology
- How AF relates to the DSP workflows used when extracting them?
Existing resources :¶
Some work related to Steve's use cases, segmentation and Ontologies:¶
- SALAMI Project: Kevin Page, DaveDeRoure http://salami.music.mcgill.ca/
- The Segment Ontology: http://users.ox.ac.uk/~oerc0033/preprints/admire2011.pdf
- PopStructure Ontology: Kurt Jacobson Unpublished.
(Example available: http://wiki.musicontology.com/index.php/Structural_annotations_of_%22Can%27t_buy_me_love%22_by_the_Beatles) - Similarity Ontology: Kurt Jacobson http://grasstunes.net/ontology/musim/musim.html
Ideas/resources for new Ontologies:¶
- Steve has worked on Acoustics related ontology
- Creating a DSP ontology:
- include processing steps down to math operations
- this can take advantage to the log and math:namespaces in CWM:
- describe common DSP parameters
- create an Acoustics Ontology
- describe Musicological concepts
- describe concepts related to cognitive and perceptual issues
Currently missing features¶
- MFCC-s
- the problem here is that the definition of MFCC is slightly ambiguous in the literature,
- this is a case for describing the workflow of computation...
- Rythmogram, Beatspectrum etc...
- combined/composite features
- weighted combinations or
- statistical averages over features (maybe only relevant if separately defined somewhere...)
- RMS energy (still not included?)
This list needs to be extended based on thorough literature review.
Development issues¶
- chaining, combination, weighting
- how you associate features with arbitrary data
- summary feature types
- SM (similarity matrix) are they part of the ontoogy?
- how to describe salience, can you hear it, can you perceive, is there an agreement
- how to describe weighting, confidence
- mood, music psychology, cognition, emotion, (perception ?)
- provenance => music provenance
- deprecation and versioning
Objectives:¶
Long term goals and some concrete tasks that can be done as the outcome of the collaboration:
- A version of Sonic Annotator that produces output adhering the new ontology
- Are we making people happier by doing so?
- gradual transition period?
- extend other software toolkits; e.g. a verison of Marsyas in C++
- multitrack processing using Sonic Annotator (this feature might come along soon)
Some immediate tasks before the next meeting:¶
- collect more resources
- Verify the relationship between AF as is, and other feature/segmentation Ontologies
- what other software uses it?
- papers and literature review
- relation to projects e.g. SIEMAC
- collect features that we need
- define scope (extend the diagram of the set of ontologies: )
- collect specific application examples from existing processing chain / workflow
Collect software/projects that use/produce audio features:
- plugins (analysis, adaptive effects, adaptive synthesis)
- LADSPA,
- VAMP,
- Marsyas,
- CLAM,
- libextract,
- COMirva,
- MIRtoolbox,
- Supercollider,
- other frameworks
See graph for how this relates to existing ontologies, ontology libraries:
http://www.isophonics.net/sites/isophonics.net/files/combined-frameworks.png
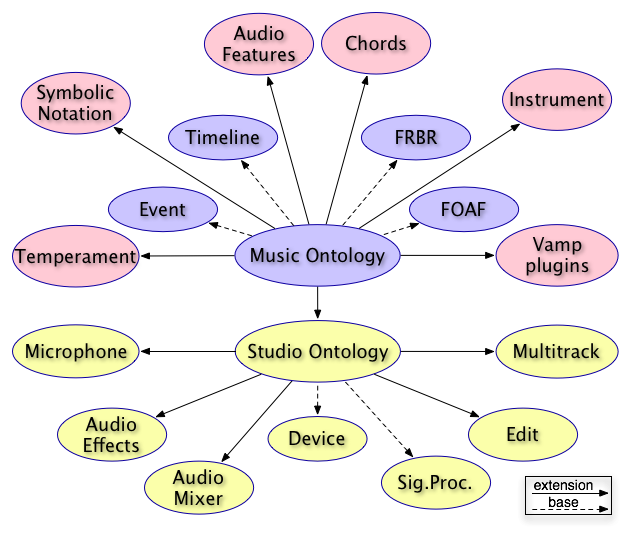{kind=link}